


Part 2. The DNA Sequencing Arms Race: Three Emerging Paradigms
Multi-part series exploring the tech and politics around short/long-read sequencing advances

In Part 1 of this series, I explored how Illumina's short-read sequencing empire, built on the foundation of breaking DNA into 150 base pair fragments and reading them with extraordinary accuracy and throughput, is facing its most serious competition in over a decade.
The genomic revolution is entering its next phase, and while short-reads have given us remarkable insights, their limits are undeniable and new challengers are coming to light. The fundamental question is no longer just: can we read DNA faster and cheaper? This next phase will invite new technical and philosophical questions on completeness, interpretation and applications.
This post specifically dives deeper into Roche’s SBX (Sequencing by Expansion), Oxford Nanopore Technologies (ONT), and Pacific Biosciences’s High Fidelity (PacBio HiFi) sequencing.
Each platform embodies a distinct philosophy about the trade-offs between speed, accuracy, read length, and accessibility. Let’s explore how each technology works, what makes it different, and the paradigm it represents in the race to decode life.
Roche’s SBX: Supercharging Short-Reads Instead of ‘Going Long’
One of the most buzzed-about and hyper recent entrants is Roche’s Sequencing by Expansion (SBX) platform, a radically different approach that intriguingly still produces short-ish reads.
SBX works by biochemically “expanding” the DNA before sequencing it. The DNA is converted into a large synthetic polymer (Xpandomer) approximately 50x longer than the original molecule, which can then be read with much higher signal to noise.
Essentially, SBX takes a small DNA fragment and blows it up like a balloon, building a base specific synthetic code around it using expandable nucleotide triphosphates (X-NTPs), this allows it to still preserve the sequence information, while making it physically longer. These modified nucleotides are incorporated by a custom evolved polymerase (Xp Synthase) into the growing Xpandomer, and then thread through a nanopore sensor. The benefit is a much clearer, amplified signal per base.
Roche claims this yields extremely high accuracy even at single-molecule level, on par with or better than current dominant sequencing by synthesis (SBS) chemistry. In fact, Roche has alluded to the fact that SBX in duplex mode (reading both DNA strands) can demonstrate an average of Q39 per base accuracy on a test genome, about an order of magnitude lower error rate than typical Illumina reads. In practical terms, that could mean fewer sequencing errors by 10 fold, virtually eliminating false variant calls due to sequencing errors.
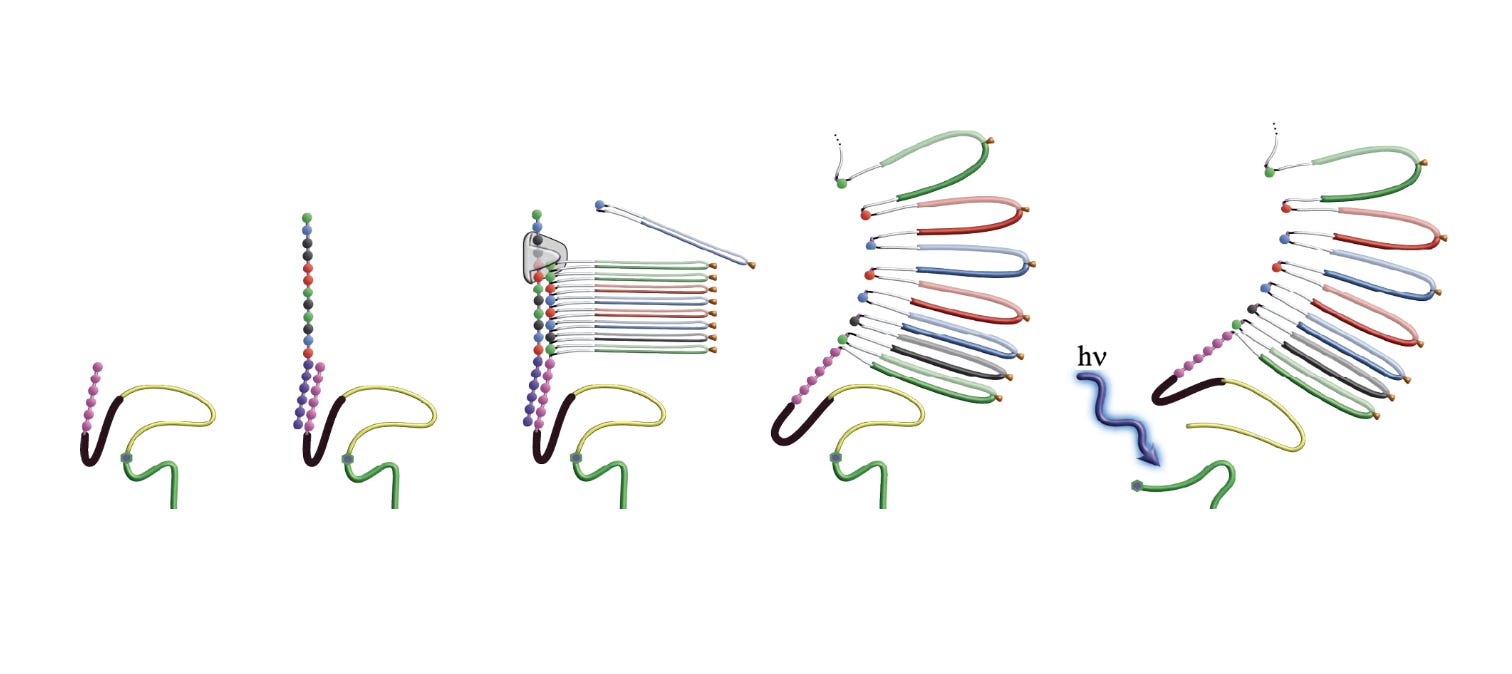
Crucially, SBX read lengths are not ultra-long, they’re in the hundreds of bases (Roche cites 150–300 bp duplex inserts and up to 1,000 bp in single-strand mode). So Roche isn’t trying to beat PacBio/ONT at the long-read game, rather, they’re trying to create the ultimate short-read machine, one that’s faster, more accurate, and more flexible than Illumina’s.
This strategy likely stems from Roche’s assessment that much of the sequencing market will continue to rely on manageable read lengths that slot into existing workflows. Many pipelines in research and clinical labs are built around short-reads, from library prep protocols to data analysis. By delivering reads of similar length/format but with better quality, SBX could plug into existing workflows with minimal disruption, while dramatically improving performance. Roche is essentially saying what if instead of going long, we make short-reads so good that long-reads aren’t necessary for most jobs?
The throughput and speed Roche is advertising for SBX are astounding (if robustly achieved): on the order of 7 whole human genomes at 30× coverage in 1 hour, translating to approximately 40 Tb over 48 hours. This is more than double the 16 Tb maximum Illumina’s NovaSeq X Plus produces with dual flow cells in the same timeframe.
Even if these are peak theoretical outputs, it suggests SBX might be significantly faster than today’s fastest, which would be a huge upgrade. Roche also emphasizes rapid turnaround: going from sample to variant report in <7 hours, which could be game changing for clinical uses like neonatal ICU sequencing or emergency pathogen ID.
What about cost? Roche has been tight-lipped on pricing, but hints at cost-efficiency via a reusable sensor. Illumina makes quite a bit selling one time use flow cells, Roche could undercut that by letting labs reuse the core chip for multiple runs (perhaps by refilling with new nanopore membranes or simply washing it). If SBX consumables are significantly cheaper per gigabase, combined with higher throughput, the cost per genome could drop below Illumina’s, even if the instrument itself is expensive.
Roche’s timeline: The company unveiled SBX publicly in February 2025 (in a webinar then at the AGBT conference where it stole the show), with early access units placed at genomics centres like the Broad Institute. A commercial launch is expected in 2025 or 2026.
If all goes well, within a couple years we may see SBX systems in many large genome centres and clinical labs, especially those that have Roche diagnostics relationships. Roche, after all, has a wide reaching global sales and support network in place. This means Roche could scale up adoption fast once the product is ready.
Could SBX destroy Illumina’s short-read monopoly? It has the ingredients to seriously challenge it: high accuracy, impressive speed, compatibility with existing analysis workflows, and the backing of a $40B company with global reach.
It’s a rare situation where a competitor has both novel tech and the corporate muscle to compete on equal footing. If SBX delivers as promised, many labs buying new sequencers might choose Roche over Illumina for the first time in ages. Illumina would be forced to respond, perhaps accelerating its own technology upgrades or dropping prices further.
However, Illumina won’t go quietly, it still has a huge installed base and ecosystem. One scenario is a true duopoly emerging in short-read sequencing, with Illumina and Roche splitting the pie. In any case, SBX signals that the era of Illumina having the short-read field to itself is ending. The sequencing community, for the first time in a long time, will have a second major supplier to choose from. Let the games begin.
Oxford Nanopore: Long-Reads, Democratization, and Agility
While Roche races to conquer speed and plugging into existing infrastructure, Oxford Nanopore Technologies (ONT) is championing a different revolution: making DNA sequencing long, portable, real-time, and accessible to all sorts of users and environments.
For some time now, they have been championing long-read, single-molecule sequencing. Its devices from the pocket-sized MinION to the hefty PromethION, sequence DNA (or RNA) by threading molecules through nanopore sensors and directly measuring base-specific disruptions in electrical current. This fundamentally different physics gives ONT distinct advantages:
Read length is essentially unlimited: you can sequence extremely long DNA fragments if you can manage to extract them intact. The record reads are now millions of bases (ONT cites >4 Mb), long enough to traverse even the largest human repeats. In practice, N50 (read/contig-length distribution statistic) read lengths of 50–100 kb are routine for high-quality DNA samples, vastly eclipsing short-reads.
Real-time data streaming: As soon as you load a sample, data start coming off. You’re only option isn’t waiting days for a run to finish. This enables adaptive sequencing where you can stop when you have enough, rapid turnaround for urgent cases, and even portable in field sequencing of e.g. pathogens without the full lab setup. During the West Africa Ebola outbreak ONT sequencer protocols were developed and used on-site to get genomes in real time for tracking mutations, something impractical for others with strict infrastructure needs.
Direct detection of DNA/RNA modifications: Nanopore sequencing reads native molecules without PCR. This includes cytosine methylation (5mC), hydroxymethylation (5hmC), N6-methyladenosine (m6A), and others, with raw read base modification accuracy as high as 99.7% depending on context. ONT can therefore output an epigenetic readout alongside the sequence, identifying methylated bases genome-wide. This is a huge edge for research into gene regulation, imprinting, and in cancer where methylation markers matter.
Flexibility and device range: ONT has a sequencer for every scenario: the $2,000 MinION (a small USB pluggable stick yielding up to 50 Gb) for quick tests or classroom demos, Flongle for low-throughput experiments up to 2Gb, the benchtop GridION, and the large PromethION scalable to hundreds of Gb. You can run just one sample or 48 samples independently. This contrasts with Illumina’s model of fewer, larger batch runs. ONT flow cells can also be stopped and restarted, and unused pores can be reused later, providing flexibility in usage.

All that said, ONT’s journey has been one of trade-offs. Historically, accuracy was the Achilles’ heel, making high confidence variant calling difficult. Through relentless improvement, new pore designs (R9 to R10.4.1), better base-calling algorithms using deep learning, and methods like duplex consensus, ONT’s accuracy has improved to where single-pass reads now often exceed 98-99%, and duplex reads can reach 99.9%.
However, a 2025 benchmarking study found that certain error modes like homopolymer-length errors or small indels persist, meaning for some applications like detecting small insertions/deletions, Illumina/PacBio still have an edge.
Cost and throughput for ONT have steadily improved. On a per gigabase basis, ONT consumables can be quite competitive: a PromethION flow cell (costing a few hundred dollars) can output 290 Gb, approaching Illumina’s cost per Gb. On smaller devices, the cost per Gb is higher. One challenge has been consistency, but ONT has steadily increased output with new chemistries (e.g. kit 14), optimized library prep, and improved pore performance.
For population-scale projects, the PromethION 48 (with 48 flowcells running in parallel) can generate tens of terabases per run, enough to sequence hundreds of human genomes on one instrument. While Illumina still wins on cost for standard 30× human WGS especially with patterned flowcells economy of scale, ONT isn’t prohibitively expensive anymore, especially when factoring in the extra info (structural variants, methylation, telomere completeness, etc.) you gain. Researchers can use a hybrid approach: Illumina for the bulk of cheap coverage, and ONT for resolving tricky regions.
Will ONT remain a niche player or scale into larger mainstream clinical markets? At the moment, nanopore sequencing is already used in genomics research, de novo assembly projects, metagenomics, and niche areas like real-time pathogen surveillance. It has seen somewhat limited clinical adoption so far. The major barriers seem to be regulatory validation and entrenched short-read pipelines.
Clinical labs value precision and regulatory body approved workflows, Illumina has a head-start there. But as ONT accuracy improves and the community gains experience, more clinical labs are experimenting with nanopore, especially for applications where short-reads just don’t cut it.
Carrier screening is a great example of where nanopore can shine in clinical settings. As population wide panels like the American College of Medical Genetics and Genomics (ACMG) 113 gene recommendation become the norm, they expose how poorly short-reads handle complex genes: SMN1, FMR1, HBA1/2, F8, CYP21A2, GBA, where big structural variants, pseudogenes, or long repeats break standard workflows. ONT’s long-reads offer a faster, cleaner solution. Recent work, like Asuragen’s validation of the AmplideX Nanopore Carrier Plus Kit, showed nanopore sequencing can resolve these tricky regions in a single run, matching legacy methods and cutting turnaround from weeks to about 48 hours. These targeted uses where ONT does what short-reads can’t may be how it carves deeper into clinical genomics.
ONT has also introduced modular pipelines (like EPI2ME software) to simplify analysis for users, and even an ONT Cloud for data processing, to lower the bioinformatics barrier. They also have a partnership with the UK Biobank to create the world’s first epigenetic dataset targeting the causes of cancer, dementia, complex disease.
A big potential for ONT is in direct RNA sequencing and even protein sequencing as they have early tech for peptide sequencing via nanopores. This could open entirely new markets beyond DNA. ONT’s adaptability, reading any nucleotide polymer, means it’s not limited to the genome; it can probe the epigenome, transcriptome, and maybe one day the proteome.
In the next few years, ONT’s trajectory will depend on whether it can reliably close the accuracy and cost gap for broad clinical use. If, say ONT advances to offer a seamless kit that produces, for example, a 30× human genome with Q40 accuracy and methylation calls for <$500 in <24 hours, it could explode into clinical genomics because that would be a one stop test for nucleotide variation, structural variation, and epigenetic markers all at once.
The company’s strategy of democratizing sequencing, making devices portable and affordable, also means it could tap markets Illumina never could like small labs, clinics in developing countries, and the growing non specialist consumer space. ONT is asking: what if you could sequence anything, anywhere? And they mean everywhere, even on the International Space Station.
For now, ONT is solidifying its niche with extremely long reads, real-time analysis, field deployment, epigenetics and gradually encroaching on Illumina/PacBio for clinical real estate as their use-case portfolio expands. It has proven staying power with growing revenues and a successful IPO in 2021, so it’s likely here to stay as a key player.
How far it’s domain extends will hinge on continuous innovation, which ONT is certainly not short on and making inroads into clinical trials and regulatory approvals.
PacBio HiFi: High-Accuracy Long Reads for the Most Demanding Genomes
PacBio was the original pioneer of long-read sequencing, and after some ups and downs, it has re-emerged as the gold standard for high-accuracy long-reads. PacBio’s current flagship is HiFi sequencing, which produces reads up to 25,000 bp long with 99.95% accuracy (Q33).
These reads are generated by circular consensus sequencing (CCS). This is done by circularizing DNA fragments and reading them multiple times, then computing a highly accurate consensus per fragment, essentially trading some throughput to correct errors. Each molecule is sequenced repeatedly via rolling circle replication, and errors from individual passes are suppressed in the consensus. This effectively produces reads that rival short-read platforms in terms of base level accuracy, while spanning long, structurally rich regions of the genome.

This unique combination makes HiFi incredibly powerful for certain applications:
De novo genome assembly: of complex genomes like plant, animal, human into near-perfect contiguous sequences, including resolving repetitive regions, structural variants, and haplotypes. HiFi reads were instrumental in the first complete telomere to telomere (T2T) assembly of a human X chromosome and later the T2T-CHM13 assembly of the full human genome.
Rare disease and cancer genomics: where discovering structural variants, tandem repeat expansions, or phased variants can crack cases that short-reads left unsolved. HiFi reads can phase heterozygous variants, resolve segmental duplications, and identify pathogenic insertions or deletions in previously inaccessible regions. Rare disease research programs have adopted PacBio for exactly this reason as it’s been shown to markedly increase diagnostic yield.
Comprehensive variant detection: PacBio HiFi can detect SNPs, indels, structural variants, and even some epigenetic marks. It has achieved scores matching short-read platforms for small variants, but with superior performance in repetitive regions where short-reads misalign. For epigenetics, HiFi detects 5-methylcytosine directly from polymerase kinetics (inter-pulse duration), enabling methylation analysis alongside sequence data from a single library prep, albeit with lower resolution than ONT’s method.
Perhaps the best testament to PacBio’s utility is that some large genome projects, like the ongoing Human Pangenome Project, rely heavily on PacBio HiFi to produce reference-grade assemblies of diverse human genomes. HiFi reads, along with nanopore, also played an essential role in finally assembling the first truly complete human genome in 2022 with no gaps, something short-reads alone simply couldn’t achieve.
It is important to note that while HiFi reads (typically 15–25 kb) excel in these high-precision applications with features spaced within 10 kb, ONT’s ultra long reads (often hundreds of kilobases) are better for untangling large, repetitive regions beyond 100 kb. However, this is also why the two technologies are complementary in telomere to telomere assemblies, where hybrid assemblers like Verkko and hifiasm integrate both to maximize resolution.
Now the major bottleneck for PacBio has long been throughput and cost. Traditional SMRT sequencing was lower throughput and more expensive per genome, limiting its use mostly to smaller-scale or specialized projects. A single Sequel II SMRT Cell 8M could produce 20–30 Gb of HiFi data, which meant you were only getting 6–10× coverage per run. So to hit 30× you’d need 3 to 5 cells at least, costing you $3,000–$5,000 in consumables alone. This is why PacBio was not a more broad realistic option for years.
But in 2023, PacBio launched the Revio system, a major leap in throughput. Revio can run 4 SMRT cells in parallel, yielding up to 480 Gb of HiFi data per run. This brings the cost down dramatically. That’s enough for a full 30× human genome on a single $995 cell, dropping the reagent cost to $330–500 per genome depending on your target coverage. You can now sequence 5–8 human genomes per day per machine, depending on loading and runtime.
The PacBio Revio platform delivers roughly a 15 fold throughput increase compared to prior Sequel IIe systems, directly addressing cost per base. That’s a night and day difference from before. While still pricier than short-reads per base, it’s within striking distance, and the value of the data is arguably higher per genome.
Other strategies to mitigate cost include targeted sequencing of genomic regions of interest (e.g. HLA loci, centromeres, VNTRs). This is enabled through droplet microfluidics with fluorescence assisted sorting, MDA pre-amplification, and CRISPR/Cas9 or hybridization capture to enrich high value targets.
PacBio has strategically positioned HiFi as the technology of choice for population-scale high-quality genomes. For example, the NIH’s All of Us research program is now sequencing a subset of samples with PacBio to capture SVs and difficult variants.
In February 2025, PacBio and Radboud UMC published a landmark study using Revio to sequence 100 rare disease cases previously unresolved by short-read tests. HiFi reads identified 93% of pathogenic variants, many missed by exomes and panels. This even included complex structural and epigenetic changes. With over 980 samples sequenced and 5,000 more planned, the study laid the groundwork for long-reads as a one test diagnostic solution.
In agrigenomics, plant and animal breeding programs are using PacBio to get better assemblies for trait mapping. HiFi is also powering a new era of transcriptomics, enabling accurate reconstruction of isoforms, fusion transcripts, and allele-specific expression. Compared to ONT, HiFi excels in precision within exonic and intronic regions and can detect low-abundance isoforms with high confidence.
The big question: Can PacBio ever compete for the mass market of routine human WGS like national newborn sequencing programs or DTC genomic testing for millions of people?
While they have already made inroads, to do so, the cost likely needs to drop to the low hundreds of dollars per genome and the throughput needs to support tens of thousands of genomes per year per instrument. Revio is a step in that direction, but others aren’t standing still on cost either. PacBio’s bet is that accuracy and long-range info will increasingly be must-haves, not luxuries, especially as medicine demands better genomic answers. If a clinical lab has been disappointed by what short-read WGS missed, they may be willing to pay a premium for HiFi sequencing for certain cases, a trend that’s already gaining momentum in high-complexity diagnostics and precision oncology.
PacBio’s niche might remain the high end of quality, not every sample needs a HiFi genome, but for those that do (e.g. unsolved disease cases, or generating reference assemblies), it’s invaluable. They were also expanding into new products. They acquired short-read sequencing technology, the now-cancelled “Onso” platform, and were exploring short-read applications of their tech, like highly accurate amplicon sequencing, etc. However, PacBio largely appears committed to being the highest quality long-read leader.
The remaining issue is cost/scale, and that gap is closing. It’s not hard to imagine a near future where a significant portion of genomic sequencing (especially in research and in clinical cases where short-read data was inconclusive) is done with HiFi long-reads. PacBio likely won’t unseat short-reads in sheer volume of genomes anytime soon, but it doesn’t need to, it just needs to capture the high-value genome market.
PacBio is providing premium sequencing to those who need or can afford the high quality prices. And as genomics applications grow, the demand for the best and not just the cheapest will grow and PacBio has the standards to set the highest quality reference database.
Who Will Own the Next Decade of Sequencing?
So who “wins”? Likely, everyone who plays it right. The pie is growing so large that multiple winners can co-exist by focusing on different segments:
Illumina could remain the volume leader in routine testing and research sequencing, if it continues to innovate and perhaps expand its foray into long-reads
Roche could become the go-to for high-end clinical laboratories and national programs that demand fast, turnkey sequencing (leveraging SBX’s speed and Roche’s clinical channels).
PacBio might dominate the precision medicine segment where completeness of genome info is paramount (rare diseases, gene therapy patient selection, etc.).
ONT might dominate applied markets (like real-time monitoring, pathogen genomics, anything needing portable or onsite sequencing) and perhaps carve out a share of clinical labs once its accuracy convinces conservative users.
The notion of an Illumina monopoly will likely fade. We’re more likely to see an oligopoly with fierce competition, or even a fragmented market where different use-cases use different tech.
Crucially, these philosophies are complementary as much as they are competitive. It’s not hard to imagine future workflows that might, for example, use ONT in the field for immediate data, SBX in the lab for rapid diagnostic confirmation, and PacBio on the back end to deeply characterize novel findings. We are entering an era where technological diversity in sequencing is greater than ever, and with it comes an explosion of possibilities.
And there’s always the chance of a dark horse: a totally new sequencing paradigm like quantum sequencing, or in-situ sequencing that sequences DNA inside cells directly. This might emerge in 5-10 years. Some researchers are quietly working away on this “fourth-generation” sequencing. It’s likely most won’t pan out soon enough to matter for this decade, but never say never.
What to Expect in Part 3
This diversity also brings challenges, which sets the stage for Part 3 of this series. With multiple sequencing paradigms thriving, we have to consider issues of interoperability, standardization, and interpretation.
I’ll also explore the global dimension of this arms race. Sequencing is not just science; it’s strategic. Illumina’s dominance has been a point of contention in trade and intellectual property disputes. Now we have major players on multiple continents: Illumina and PacBio in the US, ONT in the UK, Roche in Europe (Switzerland), BGI in China, all vying for a piece of the global genomics market. This raises questions about supply chains, national genomic sovereignty, and international collaboration vs competition.
In Part 3, I’ll look beyond the machines to explore how having a wealth of sequencing options creates both opportunities and potential challenges in building a genomics infrastructure that can serve everyone.
How do we standardize data and quality so that a human genome means the same thing regardless of platform? Will the world fragment into regions favouring one technology over another? How will regulatory policies adapt to technologies that evolve so rapidly? And as sequencing becomes ever more integral to healthcare and biotech, what are the power dynamics at play?
Could control over sequencing tech become as geopolitically charged as oil or semiconductors? These are no longer hypothetical questions.